
#FinOpen: How does artificial intelligence power the third strategic layer of Open Finance, and what is the impact of MCPs?
W FINTECHS NEWSLETTER #164
👀 Portuguese Version 👉 here
👉 W Fintechs is a newsletter focused on financial innovation. Every Monday, at 8:21 a.m. (Brasília time), you will receive an in-depth analysis in your email.

Welcome to the edition of the Finance is Open series.
Every other Wednesday, in addition to the traditional Monday editions, I will cover key topics and the latest updates on what’s happening in Open Finance, both in Brazil and around the world.
This edition of Finance is Open is brought to you by

Belvo is the leading Open Finance platform in Brazil and Mexico, providing the intelligence that enables more than 150 clients to deliver better financial services. In Brazil alone, it supports over 13 million active data consents. The company has raised R$ 400 million from global investors such as Kaszek, Quona and Y Combinator to drive innovation across Latin America.

One of the main drivers behind the creation of data-sharing infrastructures was the difficulty smaller players faced in accessing information concentrated in the hands of large banks.
This asymmetry led regulators in markets such as the United Kingdom to launch investigations that later resulted in fines for the nine largest British banks and in funding the first phase of Open Banking in the country. The intention of this first wave was to open up the ecosystem’s availability layer by turning historically closed data into accessible, standardized and structured data for new entrants.
It was through standardized APIs, stronger reciprocity in data sharing, and the establishment of quality standards for available data that the financial ecosystem became more competitive and less vulnerable to the information asymmetry that had historically created adverse selection and limited access both for new entrants and for end users themselves.
We can say that this initial stage represented the construction of the accessibility layer: it ensured that access to available data could now be done securely and in a way capable of supporting a broader data economy. A few years after implementation in countries like Brazil, the United Kingdom and across Europe, these infrastructures now intersect with the rise of tools such as artificial intelligence.
We expanded data scopes, increased the range of available APIs, created regulatory obligations and strengthened competition. And now this entire ecosystem meets technologies that are themselves enriched by data and become more capable with every new dataset integrated into them. At this point, it is clear that the availability layer has evolved and the accessibility layer has matured, but the third element of the triad is still emerging: the analytical layer capable of transforming these datasets into information that is truly useful for the players in the market.
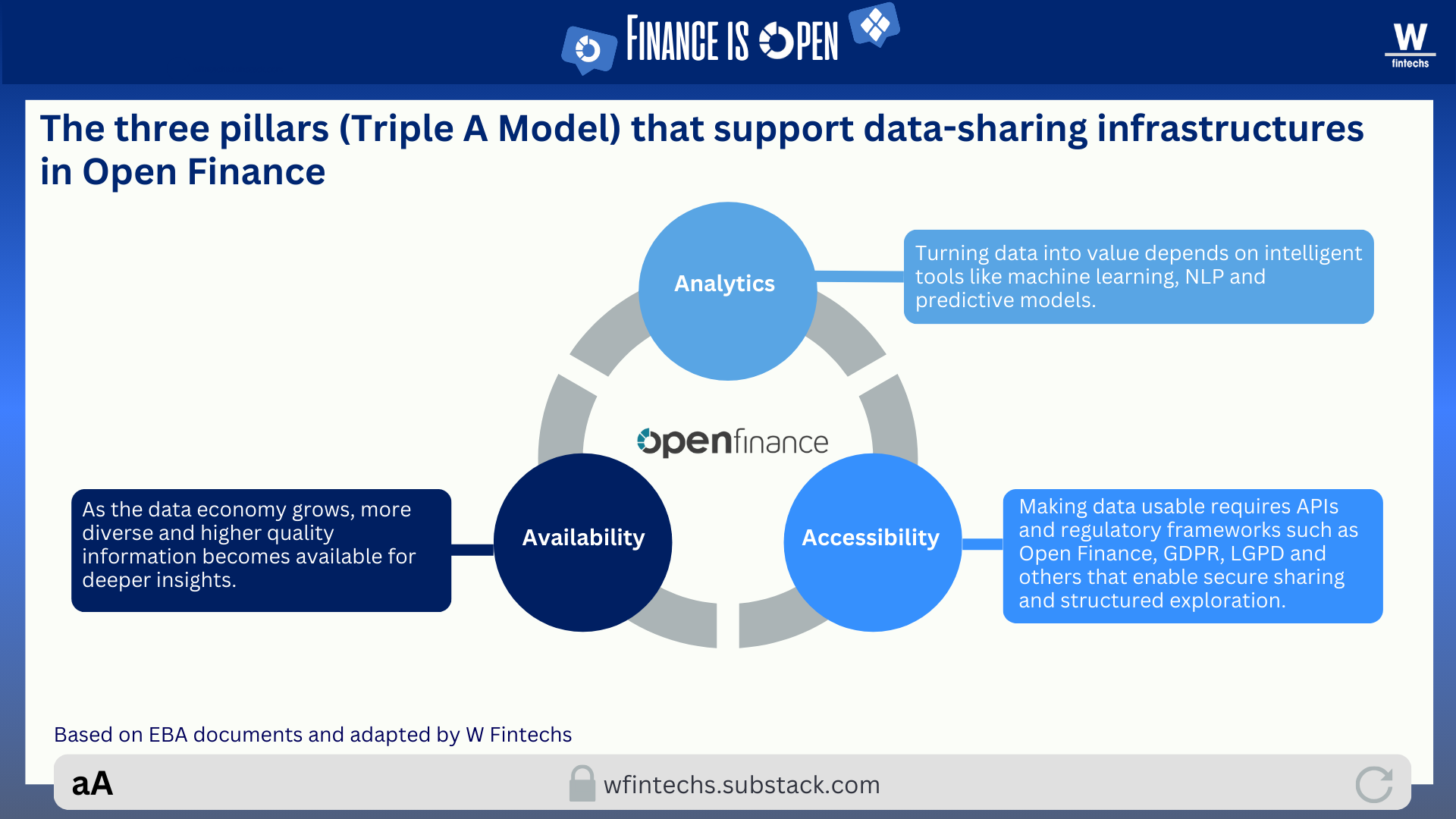
Even though Open Finance data is already being used across many use cases, and several countries now count millions of active consents, there is still a missing cognitive layer capable of interpreting this data in a contextualized way. In other words, much of the data is open, but not yet intelligible.
This is precisely where the analytics layer of the triad emerges, the layer responsible for interpreting, categorizing and predicting. Without it, data openness generates an ever-growing volume of information, but fails to translate into real value at the end point. And it is exactly this gap between access and interpretation that defines the inflection point we are experiencing now.
AI reduces the asymmetry that Open Finance, on its own, could not eliminate. Not because Open Finance is insufficient, but because its purpose was never to interpret data. Its role is to make data available and accessible.
Open Finance is similar to the internet: the internet itself does nothing beyond connecting nodes. The value arises when we add tools capable of transforming that connectivity into knowledge and utility, when the analytical layer comes into play and converts mere access to data into intelligence. This is the moment when the triad becomes complete and the ecosystem stops relying solely on the technical and regulatory infrastructure Open Finance provides.
In this edition, I explore why artificial intelligence completes the Open Finance triad by transforming data into interpretation and context. I also dive deeper into how this analytical layer opens the door for the logic behind MCPs (Model Context Protocol), a fourth A (Agency) that organizes data and systems into structures capable of reasoning and acting, further expanding Open Finance’s potential as an intelligence infrastructure.
The inflection point where AI unlocks the true potential of Open Finance data
The discussion around the potential of open data has always revolved around access, standardization and governance. But as the ecosystem evolved, it became clear that none of this creates real value if the data is not ready for use and if there are no tools capable of making that possible.
It’s no coincidence that regulators, banks and fintechs have spent the past years refining APIs, data formats and consent flows. Yet, as the ecosystem matured, it became evident that the real turning point would come when artificial intelligence entered the equation. When we look at these data-sharing infrastructures through the lens of the Triple A Model, this journey breaks down into three layers: availability, accessibility and analytics.
The first is the regulatory and technical foundation that allows APIs to expose financial data at scale. The second is the ability for third parties to access that data securely, consistently and reliably. The third (analytics) is where value is actually created, by transforming raw data into information and intelligence. What we saw globally was a huge amount of energy concentrated on the first two layers, while the third remained immature and fragmented.
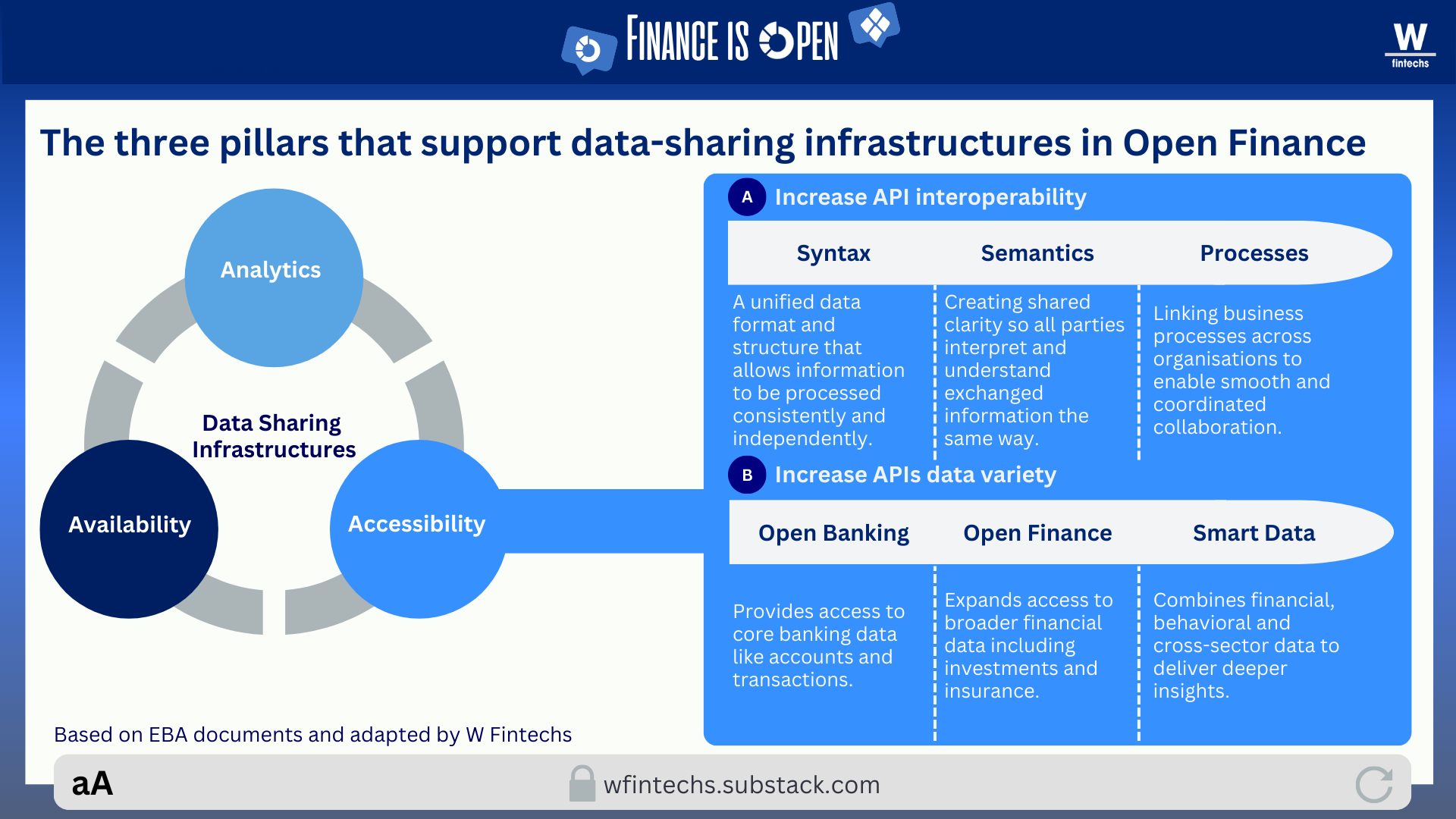
In the availability layer, there was a significant leap with the emergence of regulatory frameworks such as PSD2 in Europe and similar initiatives in Australia, India and Brazil. The volume, variety and velocity of data have increased dramatically in recent years, both inside institutions and outside of them. Yet this abundance has not erased the challenges many institutions still face, such as legacy systems, fragmented databases, differing taxonomies and inconsistent storage practices.
The accessibility layer was supposed to be the partial antidote to these issues, ensuring more standardized and interoperable access to this data. But in practice, what we saw was a mosaic of different technical standards emerging around the world. Europe, for example, operates under frameworks like Berlin Group and STET, which do not integrate seamlessly with other standards. Across the rest of the world, multiple standards also coexist, each one limited to specific types of data.
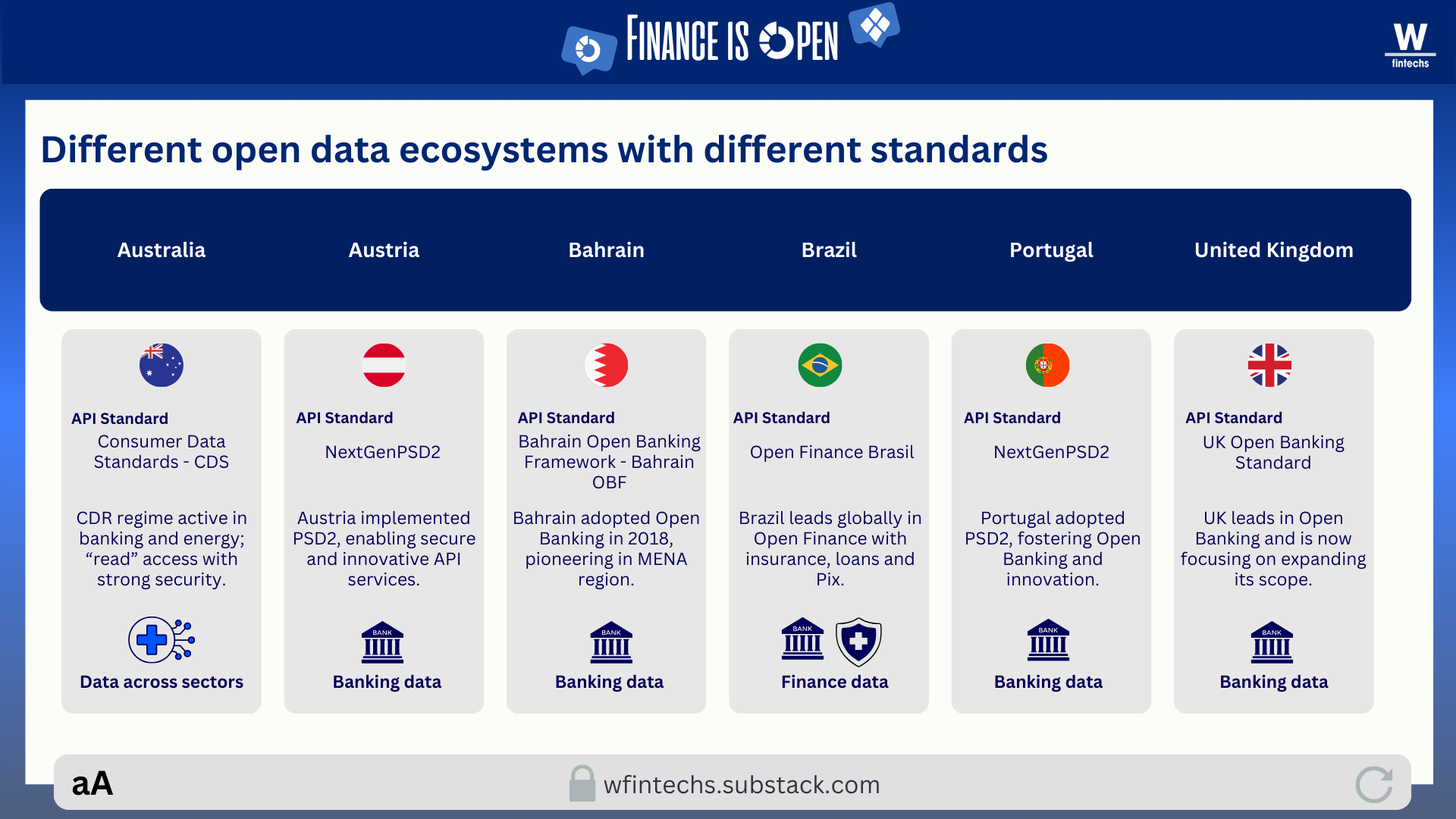
A recent study published by the UK’s Open Banking Implementation Entity showed that even in markets where APIs are well defined, data provisioning remains costly and complex 1. Banks still spend considerable effort cleaning and restructuring data before making it available, while fintechs invest additional effort reorganizing what they receive. Availability and accessibility, although essential and foundational to the viability of these infrastructures, cannot on their own generate sustainable value without analytics operating at the same level.
At this stage, the analytics layer stops being the final step and becomes the center of the process. AI begins to correct the accumulated shortcomings of the earlier layers by interpreting, organizing and enriching data that arrives broken and unstructured. Models identify patterns, detect errors and connect pieces of information that a traditional pipeline would almost never catch, precisely because pipelines follow fixed rules with limited flexibility, whereas AI learns from the data itself and continuously improves the flow.
Another interesting point in this landscape is that the financial sector shares challenges that cannot be solved in isolation, such as multi-source fraud, cybersecurity risks and systemic threat detection.
Although many institutions are working internally with AI, when it is applied collaboratively, meaning different institutions share signals, patterns and learnings without exposing sensitive individual data, AI can detect suspicious behaviors that appear across multiple places at once. This enables the identification of fraudulent patterns that cut across institutions, reduces false positives and increases the resilience of the system as a whole. In this dimension, open data stops being merely a tool for competing through better products and becomes a foundation for more integrated, collective mechanisms that enhance the security and stability of the financial ecosystem.

It is precisely in this collaborative space (the last layer in the illustration above, related to the market) that the fragmentation of Open Banking/Open Finance reveals its most serious consequences. When APIs do not communicate consistently, or when each country and institution implements its own version of the standards, it becomes extremely difficult to build truly integrated models.
A study by the EBA (European Banking Authority) identifies this as a structural bottleneck that prevents the evolution toward more intelligent financial systems 2. Another interesting finding comes from an OBL (Open Banking Limited) green paper, which shows that different LLMs interpret the Open Banking Standard (the UK API standard) in different ways, even when the specification is identical 3. This further reinforces the importance of training AI models specifically on financial standards so that they can reduce these interpretative discrepancies.
In other words, after a decade of concentrated effort on availability and accessibility, the center of gravity is finally shifting toward analytics, the top layer of the Triple A Model. This is where artificial intelligence acts in a descriptive, diagnostic and predictive manner, turning low-utility data into more strategic inputs for institutions. We can say that Open Finance is no longer just a data-access infrastructure; it is becoming an intelligence infrastructure.
The fourth A of Open Finance and the role of the Model Context Protocol (MCP)
This is exactly the moment when the MCP (Model Context Protocol) framework can be applied to Open Finance. Although the industry has already made significant progress in data access, what becomes clear is that we now have availability and accessibility, we are beginning to build the analytical layer, but we are still missing the layer that organizes, connects and transforms this data in motion.
This is where I see MCP emerging as the bridge, a protocol capable of standardizing how systems, data and agents interact, creating an environment where intelligence can operate in a more structured and precise way.
In practice, an agent within this logic is an architecture capable of observing data, interpreting context, planning actions and executing tasks autonomously and in an auditable manner. It functions within the MCP framework because it finds a standardization layer that organizes resources, tools and semantics, ensuring that its reasoning no longer depends on manual integrations or scattered rules. This foundation enables relationship agents to understand financial routines and suggest adjustments, fraud agents to cross internal and external signals to identify anomalies, and compliance agents to review events and generate reports aligned with specific regulations.
When this reasoning is applied to Open Finance, the ecosystem stops behaving like a collection of APIs and begins to function as an environment unified by a contextual layer. This layer is composed of domain-specific MCP servers, such as accounts, transactions, payments, identity, fraud, compliance. Each server not only exposes data but also provides possible actions, allowing agents to interact with the environment in a concrete way by simulating scenarios, triggering routines or generating analyses without relying on manual integrations.
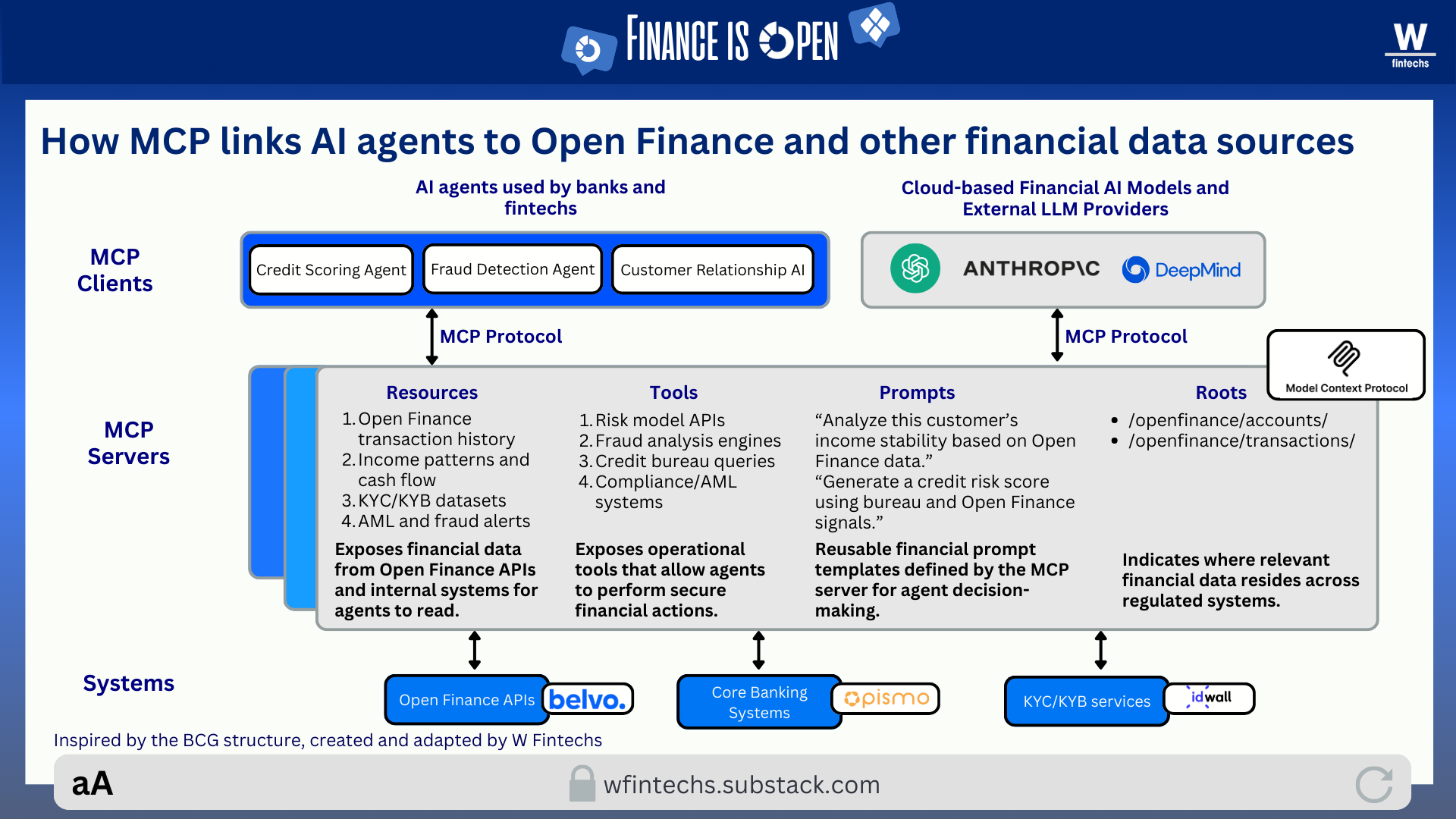
This shift adds a fourth pillar to the traditional Triple A framework. Availability and accessibility remain essential, and analytics continues to be the layer where value is created, but a new component emerges: agency. This layer allows systems to move beyond reacting to queries and instead anticipate needs, coordinate flows, generate explanations and adjust decisions according to internal policies. In practical terms, the infrastructure stops being merely a channel for access and becomes an environment capable of making contextualized decisions.
From this perspective, instead of each institution maintaining its own integrations for different providers and standards, MCP servers can encapsulate that complexity. The agent does not need to know how each country defines an account or the exact schema for a transaction, the MCP server handles those differences.
This, I believe, is where we begin to see a new level of real utility in Open Finance. Today, only a few models are truly trained to handle the diversity and sensitivity of financial data. In Brazil, initiatives like Pierre Finance are emerging with the goal of developing specialized models built on local banking structures. Internationally, there are movements such as the e2e MCP, aimed at creating interpretative layers for APIs and global standards. This approach can be expanded to experiments in credit, fraud detection and automatic reconciliation.
According to Belvo’s Co-CEO, Oriol Tintoré, one of the reasons Open Finance data is not widely used in Brazil today is the heavy reliance on manual steps in data analysis and in defining use cases. Many teams manually analyze extremely complex datasets and then ideate potential use cases, resulting in subsequent projects that take a long time to implement. This limits and reduces the impact of Open Finance.
To address this, Belvo is investing in the next generation of infrastructure using AI Agents, based on the belief that these tools can automate and scale the personalization of financial services.
In other words, once these pieces come together, we will begin to see a more mature data-sharing ecosystem, where the three As of the Triple A Model join the fourth A (agency) fully powered by AI. Open Finance will stop being merely a connection architecture and will become an architecture of interpretation and decision-making that is far more coordinated and contextualized. If this trajectory continues, we will see a financial system that is genuinely more collaborative across institutions, where financial data circulates with greater contextualization and enables organizations to build products, models and services that learn in real time from the ongoing evolution and availability of the data economy.
If you know anyone who would like to receive this e-mail or who is fascinated by the possibilities of financial innovation, I’d really appreciate you forwarding this email their way!
Until the next!
Walter Pereira
Disclaimer: The opinions expressed here are solely the responsibility of the author, Walter Pereira, and do not necessarily reflect the views of the sponsors, partners, or clients of W Fintechs.
https://www.openbanking.org.uk/insights/ai-and-open-finance-shaping-the-future-of-financial-innovation/
https://www.abe-eba.eu/wp-content/uploads/2025/07/eba_201906_obwg_ai_in_the_era_of_open_banking_double_page_view-5.pdf
https://www.openbanking.org.uk/insights/ai-and-open-finance-shaping-the-future-of-financial-innovation/
Fantastic framing on the analytics layer as the missing piece of Open Finance. The point about data being open but not yet intelligible really hits. Most discussions focus on availability and accessibility, but you're right that institutions still spend huge effort cleaning what they receive. MCP as the fourth A (agency) is a smart lens for where this is heading, especially if servers can encapsulate complexity across different standards.