


#114: O dilema da economia de dados: como as instituições podem transformar oportunidades em receita?
W FINTECHS NEWSLETTER #114
👀 English Version 👉 here
Esta edição é patrocinada pelo

O Iniciador habilita Instituições Reguladas e Fintechs no Open Finance, com uma Plataforma SaaS de tecnologia white-label que reduz sua sobrecarga tecnológica e regulatória:
Dados Financeiros em tempo-real
Iniciação de Pagamento
Servidor de autorização para Detentoras (Compliance Fase 3)
Somos Top 5 dos maiores Iniciadores de Pagamento (ITP) do Brasil em volume de transações.
💡Traga sua empresa para a W Fintechs Newsletter
Alcance um público nichado de fundadores, investidores e reguladores que leem toda segunda-feira uma análise profunda do mercado de inovação financeira. Clique 👉aqui
👉A W Fintechs é uma newsletter focada em inovação financeira. Toda segunda-feira, às 8:21 a.m. (horário de Brasília), você receberá uma análise profunda no seu e-mail.
A cada dia que passa, estamos gerando mais dados. Para o sistema financeiro, o resultado dos dados — a informação — é a peça fundamental que move as decisões, o consumo e o crédito.
A internet e a digitalização permitiram que nosso comportamento, antes exclusivamente no mundo real e sem muito registro além da memória humana, fosse documentado em uma espécie de livro digital. Esse livro (leia-se bancos de dados) passou a ser integrado a outros livros, de outras editoras (leia-se empresas), dando vida a um livro ainda maior sobre a vida de cada um de nós.
Na vida real, pode ser que não acreditemos ter algum valor social, mas, para a internet, pode ter certeza de que você, independentemente de quem seja, tem valor. Através do seu comportamento, você enriqueceu algum modelo que foi, é e será usado a favor ou contra você, ou qualquer outro indivíduo.
Desde as primeiras informações de crédito registradas em um bloco de notas da Casas Bahia (o crediário dos anos 1950) até o mais moderno data stack do Nubank ou Itaú, os dados ali contidos representam uma forma valiosa de conhecer e prever comportamentos. Demorou um pouco para entendermos que, se o dinheiro é realmente composto apenas de pequenos pedaços de dados, então os dados em si têm seu próprio valor — e também podem ser monetizados.
A evolução da internet mostra bem isso: nas fases 1 e 2 da web, o ‘data rights’ ganhou ainda mais força, após o vazamento e o uso indevido dos dados por diversos grandes players — infraestruturas como o Open Finance são a concretização desse direito —; já na fase 3, começamos a falar sobre ‘data ownership’ com a tokenização e blockchain. Mas o processo para que tenhamos realmente uma economia de dados onde o usuário é o dono de seus dados é bem mais complexo e desafiador do que parece (escrevi sobre 👉 aqui).

O boom dos dados
Com o aumento da capacidade de armazenamento e processamento de dados, a economia de dados surgiu na década de 1990, quando o PIB global era de US$ 20 trilhões. Desde então, esse valor saltou para US$ 90 trilhões em 2020. Alguns estudos de 2018 estimavam que até 2025 a economia global de dados poderia gerar um acréscimo de até US$ 3 trilhões por ano no PIB global, justamente por conta das melhorias na eficiência, inovação e a criação de novos negócios que isso traria.
O cenário ficou ainda mais interessante a partir de 2021, quando a pandemia obrigou o mundo a se conectar e interagir quase que exclusivamente de forma digital. Esse novo comportamento gerou um salto na criação de dados. Uma taxa de crescimento que não era possível observar nos anos anteriores, embora tivéssemos tido a chegada dos smartphones e o avanço do armazenamento em cloud.
Apesar de estarmos criando mais dados do que nunca, apenas 10% deles são únicos, enquanto os outros 90% são replicados1. Entre 2020 e 2024, a previsão é que essa proporção mude de 1:9 para 1:10, o que significa que, para cada dado original criado, haverá 10 cópias.
A inteligência artificial generativa, como o GPT, ao mesmo tempo em que transforma a maneira como automatizamos e aceleramos processos em até 40% 2, estão contribuindo também para esse fenômeno de replicação massiva de dados, fazendo com que atinjamos 180 zettabytes de dados criados, coletados e copiados até 2025.
A cada interação, a IA reutiliza grandes quantidades de informações pré-existentes para gerar conteúdo. Isso facilita o acesso à informação, mas também intensifica a criação de dados redundantes. Embora esses modelos aumentem o volume de dados copiados, eles também sintetizam e resumem informações, criando novos conhecimentos. No entanto, a quantidade de dados "novos" gerados pode ser desproporcional em relação aos dados reutilizados, contribuindo para o crescimento exponencial dos dados.
O verdadeiro desafio, portanto, não está apenas na geração de mais dados. Está em produzir informações que, de fato, tragam algo novo à mesa, que façam a diferença. O futuro da inovação não será movido por um simples acúmulo de informações, mas pela habilidade de filtrar o que importa, tirando proveito de tecnologias que conseguem ver o que, até então, passava despercebido.
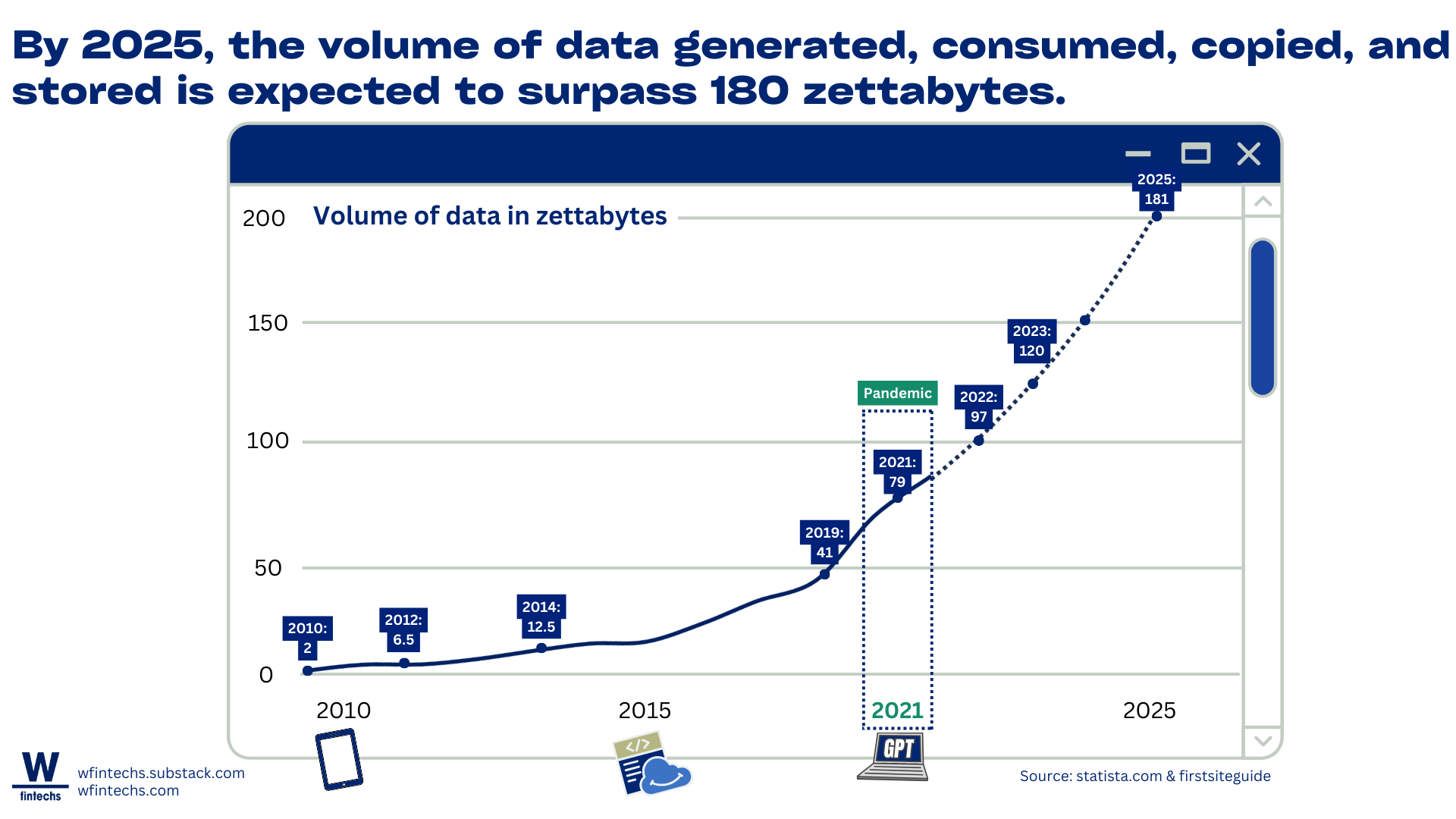
A qualidade e dispersão dos dados
A replicação dos dados algumas vezes advém de um cenário onde há pouca ou nenhuma integração entre diferentes bases de dados. Sendo assim, cada departamento dentro da empresa pode criar e gerenciar suas próprias cópias, gerando redundâncias que não apenas consomem mais espaço de armazenamento, mas também comprometem a consistência e a precisão dos dados.
Por exemplo, uma equipe de vendas pode ter seu próprio banco de dados de clientes, enquanto o departamento de marketing pode utilizar uma versão diferente dessa mesma lista, resultando em desatualizações e divergências nas informações. Essa falta de integração também prejudica a tomada de decisões, já que 50% das empresas dizem que não há informações necessárias disponíveis 3, o que atrasa suas decisões de negócios.
Quando as informações estão fragmentadas, as decisões se tornam menos ágeis. Isso é agravado pelo fato de que 40% das empresas não confiam na qualidade dos dados usados nas análises 4, o que faz com que tenham um custo anual de US$ 12,9 milhões. Outro impacto da má qualidade e da dispersão dos dados está no tempo perdido pelos analistas. Na área financeira, os analistas gastam cerca de 30% do seu tempo reconciliando dados de diferentes fontes 5, o que aumenta os custos operacionais e reduz a produtividade das equipes, que poderiam se concentrar em análises mais estratégicas para o negócio.
Por outro lado, empresas que centralizam e integram seus dados ganham vantagens significativas, como mostrou uma pesquisa da McKinsey, tendo dezenas de vezes mais chances de adquirir e reter clientes, além de aumentar sua lucratividade. No entanto, muitas empresas ainda não conseguem integrar seus dados de maneira coesa, sendo assim, fazendo com que o maior obstáculo para as análises avançadas não seja a falta de habilidade ou de tecnologia, mas sim o velho e simples acesso a dados de qualidade, como escreveu a Harvard Business Review neste artigo.
A criação de valor com dados
Então, chegamos a dois grandes desafios da economia de dados: a replicação e dispersão de dados em diferentes fontes. Com mais de 80% desses dados sendo não estruturados e não padronizados 6, o verdadeiro obstáculo para as empresas hoje é como converter essa massa de dados em informações realmente benéficas para as tomada de decisões estratégicas, eficiência dos negócios e para a criação de valor para seus clientes.
Algumas empresas têm dificuldade em acessar dados relevantes, pois seus ecossistemas são fechados, o que impede análises profundas, contribuindo para o mercado de venda de dados, que já vale US$ 10,7 bilhões 7. Outras empresas possuem os dados, mas não sabem como utilizá-los de forma eficaz, impulsionando o crescimento do mercado de analytics as a service, que pode atingir cerca de US$ 101 bilhões até 2026 8.
No mercado financeiro, o Open Finance e outros ecossistemas de dados abertos também têm aberto uma nova era para a criação de oportunidades, uma vez que trazem mais dados para dentro das instituições financeiras. No report que a W Fintechs lançou em setembro de 2024 (link 👉 aqui), é possível já identificar avanços interessantes em termos de usabilidade não apenas da infraestrutura disponível, mas também dos dados que essa infraestrutura habilitou ser compartilhado.
Muitas instituições estão explorando três áreas principais: gestão financeira, seja para pessoas ou empresas; ofertas personalizadas; ou iniciação de pagamento.

Há duas etapas principais na participação dentro do Open Finance: (i) a exposição de dados e (ii) o consumo desses dados, que se refere ao uso efetivo para fins específicos.
A primeira etapa envolve as instituições solicitando o consentimento explícito dos usuários para o compartilhamento de dados. No Open Finance do Brasil, há um regime de reciprocidade, o que significa que, ao coletar dados de uma instituição B, a instituição A também deve compartilhar os mesmos dados com a instituição B. Isso garante um equilíbrio na troca de informações e promove mais competição no ecossistema.
Na etapa seguinte, que diz respeito ao consumo dos dados, surgem muitas oportunidades. Muitas instituições reconhecem o valor na fase anterior, mas, ao chegar ao uso dos dados, enfrentam o paradoxo da escolha: com uma diversidade de casos de uso disponíveis, decidir qual caminho seguir não fica muito claro para muitas delas.
Alguns players, como a Ozone API, uma empresa britânica que ajuda bancos e instituições financeiras a entrarem em conformidade com o Open Finance, relatam que muitas instituições se encontram em uma situação de “analysis paralysis”, incapazes de organizar e priorizar seus casos de uso.

A forma como poderiam ultrapassar esse obstáculo é através da promoção de um alinhamento mais claro entre as áreas da instituição quanto ao propósito de participação no ecossistema, ou seja, definir claramente os objetivos e o retorno esperado nesta participação.
No Brasil e em muitos outros países, onde a participação é obrigatória para a maioria das instituições, muitas vezes elas não conseguem desenvolver propósitos claros para sua atuação, limitando-se a participar por exigência regulatória. Uma forma possível, é através de ferramentas como Design Thinking que poderia ajudar a analisar um conjunto de oportunidades, estruturá-las de acordo com a estratégia da empresa e priorizar sua implementação.

As fases de research e insights são onde as instituições irão se desvincular do efeito FOMO (Fear of Missing Out), ou seja, ela irá de fato alinhar sua participação no Open Finance de acordo com suas necessidades e capacidades internas. Esse alinhamento é fundamental para que a instituição não apenas participe por uma obrigação regulatória, mas também utilize a experiência e os dados que esta infraestrutura traz de maneira mais estratégica, promovendo inovações que realmente atendam às demandas de seus clientes.
Após o levantamento de dados internos, a instituição deve iniciar o processo definindo objetivos claros e mensuráveis. Esses objetivos podem incluir a melhoria da experiência do cliente, aumentando a satisfação ao simplificar processos e melhorar a transparência nas taxas; o aumento da participação de mercado, captando novos clientes através da oferta de produtos financeiros competitivos e personalizados; a eficiência operacional, reduzindo custos e tempo do processo de contratação de um produto financeiro; e o desenvolvimento de novas funcionalidades, como ferramentas de comparação ou calculadoras, que atendam realmente às necessidades dos clientes.
Na etapa de ideação, entra a matriz de oportunidades. Aqui a instituição vai poder visualizar e priorizar as diferentes iniciativas que podem ser exploradas dentro do contexto do Open Finance. Uma vez que as oportunidades foram identificadas e priorizadas, a instituição pode passar à fase de protótipos, onde as soluções escolhidas são desenvolvidas em formato de protótipos para testes com perfis específicos de usuários reais.
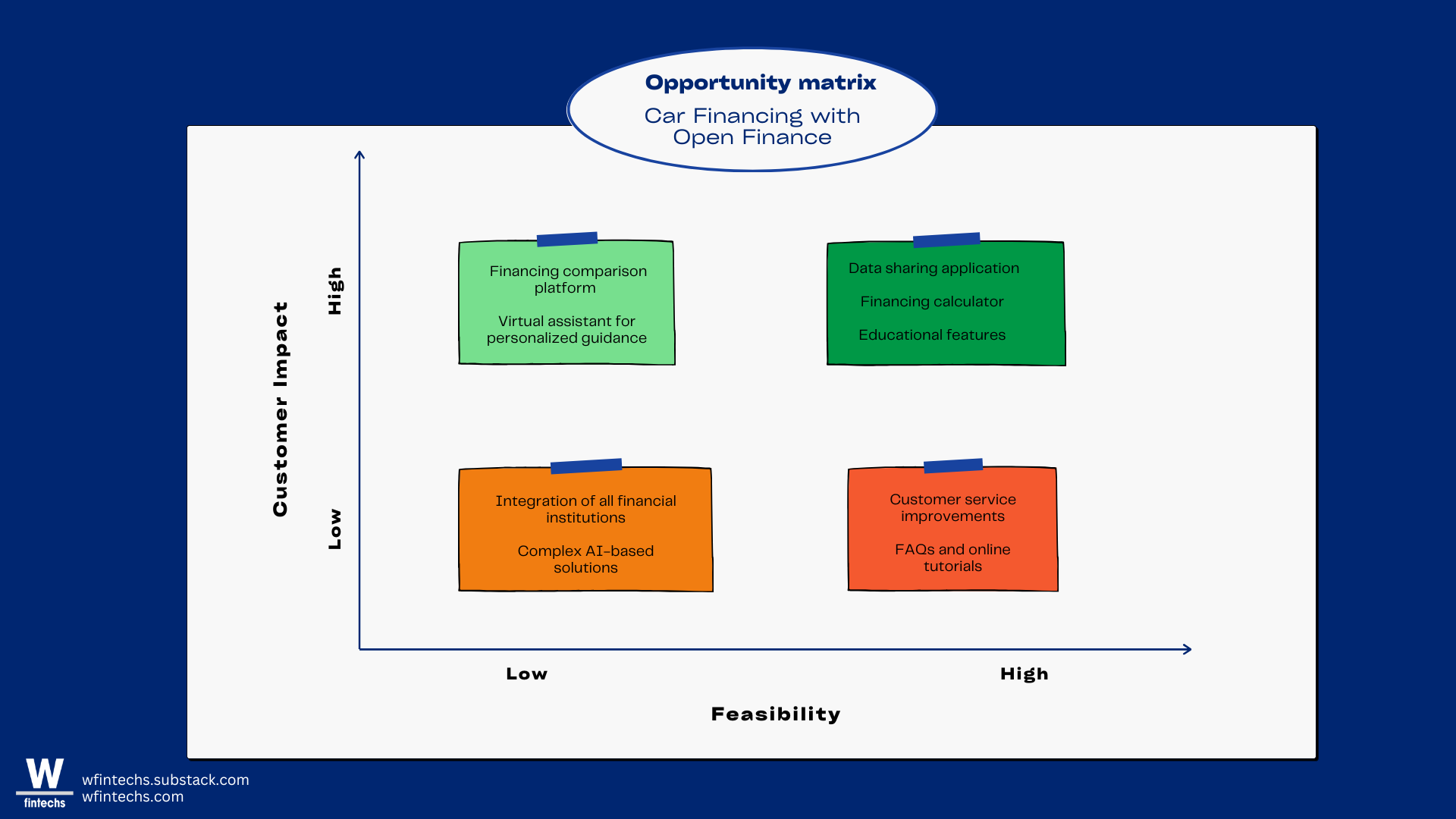
Outras formas possíveis para criação de valor
Uma outra forma de criar experiências realmente benéficas para os usuários é a instituição começar explorando os dados que já possui. É compreensível que as tendências que estão moldando a economia de dados como a inteligência artificial generativa, regulamentações como o Open Finance e novos comportamentos dos usuários estão direcionando o mercado para uma nova geração de empresas data-driven.
O verdadeiro valor estará na capacidade de transformar esses dados em insights altamente personalizados que atendam às necessidades financeiras individuais dos consumidores. Um exemplo claro dessa transformação é a possibilidade de notificar um cliente sobre a oportunidade de transferir dinheiro de sua conta corrente para a poupança com base em sua situação financeira. O Nubank fez um caso interessante neste sentido, notificando os usuários quando estavam prestes a entrar no cheque especial que tem juros altíssimo.
Contudo, essa transição não será simples. Embora o Open Finance seja uma exigência regulatória para muitas instituições, começar pelos próprios dados disponíveis — aproveitando as transações das contas já existentes dos clientes — tornaria mais simples a limpeza e transformação dos dados. Isso permitiria a extração de novos insights de forma mais eficaz, criando uma jornada preparatória para o Open Finance. Esse approach é especialmente útil para instituições que ainda não estão explorando dados de forma significativa em benefício dos clientes. Após essa fase inicial, a empresa pode então integrar dados externos, solicitando que os clientes conectem suas contas de outras instituições.

Hoje, consumidores estão entregando seus dados sem receber quase nada em troca. Isso é insustentável no longo prazo. À medida que mais empresas acordam para o valor desses dados e começam a desenvolver novas soluções com eles, os consumidores vão perceber o poder que têm em mãos. E quando isso acontecer, a pergunta inevitável será: o que eu ganho com isso?
Para sobreviver nesse ambiente cada vez mais competitivo, as empresas terão que dar uma resposta clara. Não basta pedir dados, será preciso oferecer algo de valor real. E é aqui que os times de produto e UX enfrentam seu maior desafio: gerar benefícios tangíveis, algo que faça o consumidor pensar "vale a pena compartilhar". O desafio não será mais apenas atrair consentimentos, mas retê-lo.
Saúde e paz,
Walter Pereira
Disclaimer: As opiniões expressas aqui são de total responsabilidade do autor, Walter Pereira, e não refletem necessariamente as opiniões dos patrocinadores, parceiros ou clientes da W Fintechs.
https://www.statista.com/statistics/1185888/worldwide-global-datasphere-unique-replicated-data/
https://thebusinessdive.com/ai-productivity-statistics#top-ai-productivity-statistics-in-2024
https://bi-survey.com/decision-making-no-information
https://bi-survey.com/decision-making-no-information
https://www.pwc.com.br/pt/consultoria-negocios/assets/bench_financas_baixa.pdf
https://www.cio.com/article/220347/ai-unleashes-the-power-of-unstructured-data.html
https://www.statista.com/statistics/1132224/worldwide-daas-market/
https://www.statista.com/statistics/1234242/analytics-as-a-service-global-market-size/