


#114: The Data Economy Dilemma: How Financial Institutions Can Turn Opportunity into Revenue?
W FINTECHS NEWSLETTER #114
👀 Portuguese Version 👉 here
This edition is sponsored by

Iniciador enables Regulated Institutions and Fintechs in Open Finance, with a white-label SaaS technology platform that reduces their technological and regulatory burden:
Real-time Financial Data
Payment Initiation
Issuer Authorization Server (Compliance Phase 3)
We are a Top 5 Payment Initiator (ITP) in Brazil in terms of transaction volume.
💡Bring your company to the W Fintechs Newsletter
Reach a niche audience of founders, investors, and regulators who read an in-depth analysis of the financial innovation market every Monday. Click 👉here
👉 W Fintechs is a newsletter focused on financial innovation. Every Monday, at 8:21 a.m. (Brasília time), you will receive an in-depth analysis in your email.
Every day, we are generating more data. For the financial system, the outcome of data — information — is the key element driving decisions, consumption, and credit.
The internet and digitalization have allowed our behavior, once limited to the physical world and mostly undocumented beyond human memory, to be recorded in a kind of digital ledger. This ledger (databases) has become interconnected with other ledgers from other publishers (companies), creating an even larger record of each of our lives.
In the real world, we might not feel like we have much social value, but online, rest assured, you do — no matter who you are. Through your behavior, you've enriched some model that has been, is, and will be used for or against you or any other individual.
From the first credit notes recorded in a notebook at Casas Bahia — one of Brazil’s largest retail chains known for making credit accessible through installments since the 1950s — to the most modern data stacks at Nubank or Itaú, the data contained within them represent a valuable way to understand and predict behaviors. It took us a while to grasp that if money is really just made up of small pieces of data, then the data itself holds its own value — and it can be monetized too.
The evolution of the internet clearly shows this: in web phases 1 and 2, 'data rights' gained even more importance, especially after data breaches and the misuse of data by big players — infrastructures like Open Finance are the realization of that right. Now, in phase 3, we're starting to talk about 'data ownership' through tokenization and blockchain. However, the path to truly having a data economy where users own their data is much more complex and challenging than it seems (I wrote about it 👉 aqui).

The Data Boom
With the increase in data storage and processing capabilities, the data economy emerged in the 1990s, when the global GDP was $20 trillion. Since then, this figure has skyrocketed to $90 trillion by 2020. Some 2018 studies estimated that by 2025, the global data economy could contribute an additional $3 trillion per year to global GDP, thanks to improvements in efficiency, innovation, and the creation of new businesses.
The scenario became even more interesting after 2021, when the pandemic forced the world to connect and interact almost exclusively online. This shift in behavior led to a surge in data creation, with a growth rate that had not been observed in previous years, despite the rise of smartphones and the advancement of cloud storage.
Although we're generating more data than ever, only 10% is unique, while the other 90% is replicated1. Between 2020 and 2024, this ratio is expected to shift from 1:9 to 1:10, meaning that for every original piece of data created, there will be 10 copies.
Generative AI, like GPT, while transforming how we automate and accelerate processes by up to 40% 2, is also contributing to this massive data replication phenomenon, leading to a projected 180 zettabytes of data created, collected, and copied by 2025.
With each interaction, AI reuses large amounts of pre-existing information to generate content. This makes information more accessible but also intensifies the creation of redundant data. While these models increase the volume of copied data, they also synthesize and summarize information, creating new knowledge. However, the amount of "new" data generated may be disproportionate to the reused data, contributing to exponential data growth.
The real challenge, therefore, isn’t just about generating more data. It’s about producing insights that truly bring something new to the table, that make a difference. The future of innovation won’t be driven by simply amassing information, but by the ability to filter what matters, leveraging technologies that can uncover what has previously gone unnoticed.
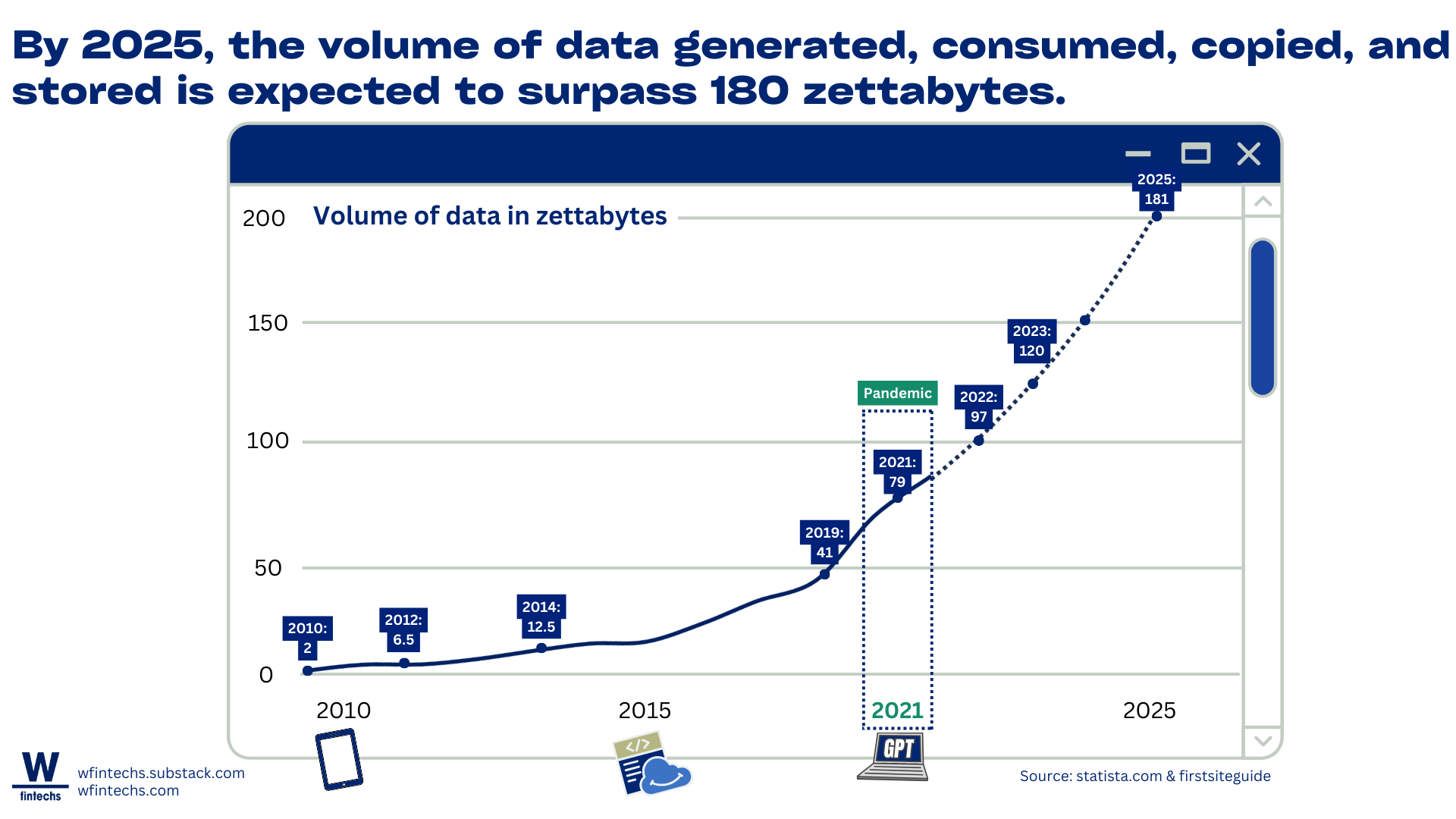
Data Quality and Dispersion
Data replication often stems from a lack of integration between different databases. This allows each department within a company to create and manage its own copies, generating redundancies that not only consume more storage space but also compromise data consistency and accuracy.
For example, a sales team may have its own customer database, while the marketing department might use a different version of the same list, leading to outdated and conflicting information. This lack of integration also hampers decision-making, as 50% of companies report not having the necessary information availables 3, delaying business decisions.
When information is fragmented, decisions become slower. This issue is worsened by the fact that 40% of companies do not trust the quality of the data used in analyses 4, leading to an annual cost of $12.9 million. Poor data quality and dispersion also waste analysts' time. In the financial sector, analysts spend around 30% of their time reconciling data from different sources 5, increasing operational costs and reducing productivity — time that could be better spent on more strategic business analyses.
On the other hand, companies that centralize and integrate their data gain significant advantages. A McKinsey study showed they are dozens of times more likely to acquire and retain customers, as well as boost profitability. However, many companies still struggle to integrate their data cohesively. As a result, the biggest obstacle to advanced analytics is not a lack of skills or technology but simply access to quality data, as highlighted by Harvard Business Review in this article..
Creating Value with Data
Then we face two major challenges in the data economy: the replication and dispersion of data across different sources. With over 80% of this data being unstructured and non-standardized 6, the real obstacle for companies today is how to convert this vast amount of data into truly beneficial insights for strategic decision-making, business efficiency, and value creation for customers.
Some companies struggle to access relevant data because their ecosystems are closed, preventing deep analysis. This fuels the data-selling market, which is already valued at $10.7 billion 7. Other companies have the data but don’t know how to use it effectively, driving the growth of the analytics-as-a-service market, which could reach around $101 billion by 2026 8.
In the financial market, Open Finance and other open data ecosystems are ushering in a new era of opportunity by bringing more data into financial institutions. According to the report released by W Fintechs in September 2024 (link 👉 here), significant progress has already been made in terms of not only utilizing the available infrastructure but also the data that this infrastructure enables to be shared.
Many institutions are exploring three main areas: financial management for individuals or businesses, personalized offers, and payment initiation.

There are two main stages in participating in Open Finance: (i) data exposure and (ii) data consumption, which refers to the effective use of data for specific purposes.
The first stage involves institutions requesting explicit consent from users for data sharing. In Brazil's Open Finance ecosystem, there is a reciprocity regime, meaning that when institution A collects data from institution B, A must also share the same data with B. This ensures a balanced exchange of information and fosters more competition in the ecosystem.
The next stage, which concerns data consumption, presents many opportunities. While many institutions recognize the value in the previous phase, when it comes to actually using the data, they face a "paradox of choice". With a wide range of use cases available, it’s often unclear which path to follow.
Some players, like Ozone API, a UK-based company helping banks and financial institutions comply with Open Finance, report that many institutions experience “analysis paralysis”, unable to organize and prioritize their use cases.

One way to overcome this obstacle is by promoting clearer alignment among the institution’s departments regarding the purpose of participating in the ecosystem. This means clearly defining the objectives and expected return on this participation.
In Brazil and many other countries, where participation is mandatory for most institutions, they often fail to develop clear goals for their involvement, limiting their actions to merely meeting regulatory requirements. One possible approach is to use tools like Design Thinking, which can help analyze a range of opportunities, structure them according to the company's strategy, and prioritize their implementation.

The research and insights phases are where institutions will break free from the FOMO (Fear of Missing Out) effect. In this stage, they will align their participation in Open Finance according to their internal needs and capabilities. This alignment is essential for the institution to not just participate due to regulatory obligations, but also to strategically leverage the experience and data that this infrastructure provides, fostering innovations that truly meet their customers' demands.
After gathering internal data, the institution should begin the process by defining clear and measurable objectives. These objectives may include improving customer experience by increasing satisfaction through simplified processes and enhanced transparency in fees; increasing market share by attracting new customers through competitive and personalized financial product offerings; achieving operational efficiency by reducing costs and time in the process of acquiring a financial product; and developing new features, such as comparison tools or calculators, that genuinely address customer needs.
In the ideation phase, the opportunity matrix comes into play. Here, the institution will be able to visualize and prioritize different initiatives that can be explored within the context of Open Finance. Once the opportunities are identified and prioritized, the institution can move on to the prototyping phase, where the selected solutions are developed in prototype format for testing with specific profiles of real users.
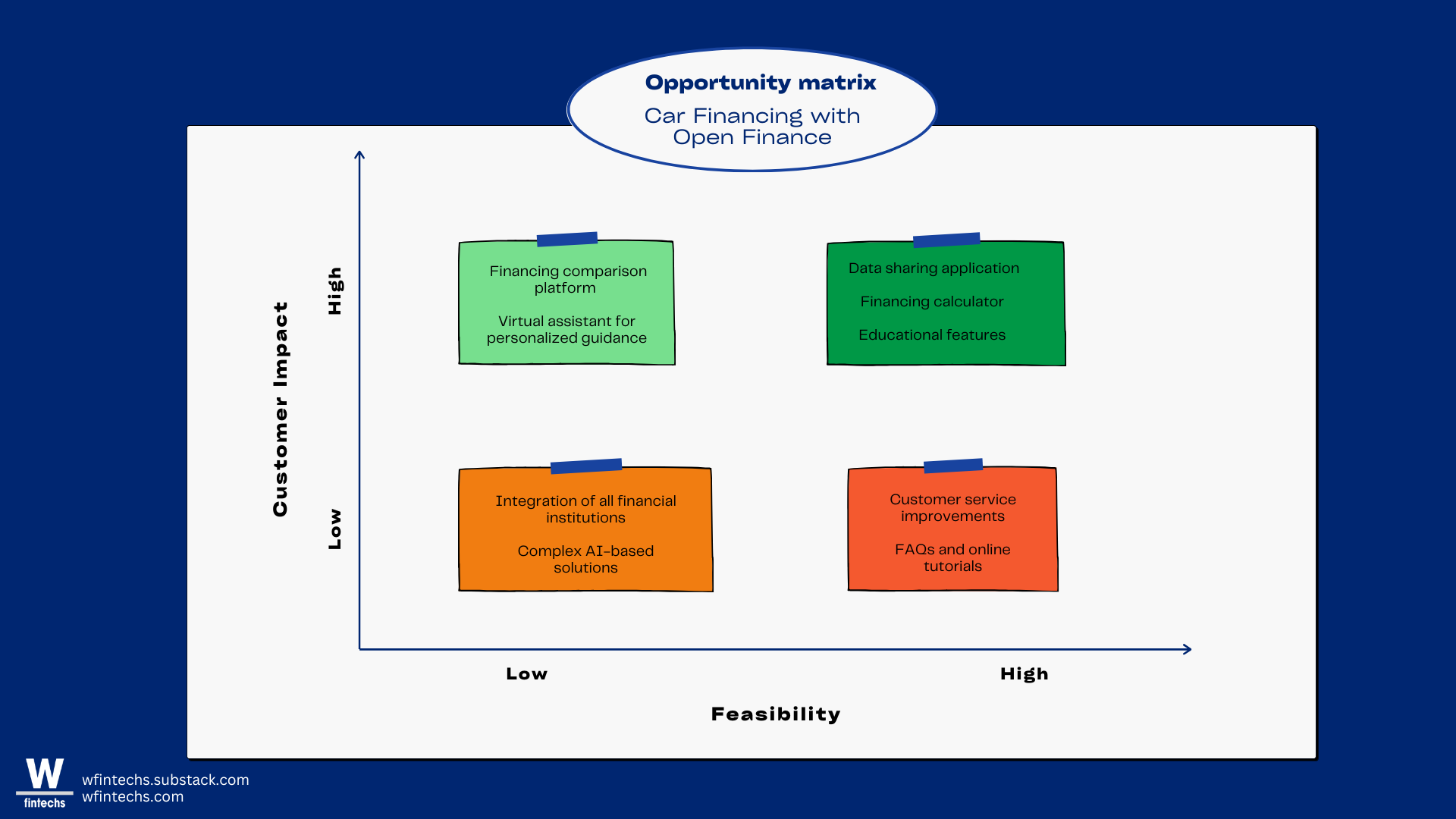
Other Possible Ways to Create Value
Another way to create truly beneficial experiences for users is for institutions to begin exploring the data they already possess. It is understandable that trends shaping the data economy, such as generative artificial intelligence, regulations like Open Finance, and new user behaviors, are driving the market toward a new generation of data-driven companies.
The true value will lie in the ability to transform this data into highly personalized insights that meet individual consumers' financial needs. A clear example of this transformation is the possibility of notifying a customer about the opportunity to transfer money from their checking account to savings based on their financial situation. Nubank has made an interesting case in this regard by notifying users when they are about to enter the overdraft, which has very high-interest rates.
However, this transition will not be simple. While Open Finance is a regulatory requirement for many institutions, starting with their own available data — leveraging transactions from customers' existing accounts — would simplify data cleaning and transformation. This approach would enable more effective extraction of new insights, creating a preparatory journey toward Open Finance. It’s particularly useful for institutions that are not yet fully leveraging data to benefit their customers. After this initial phase, the company can then integrate external data by asking customers to connect accounts from other institutions.

Today, consumers are giving away their data without receiving much in return. This is unsustainable in long-term. As more companies wake up to the value of this data and start developing new solutions with it, consumers will realize the power they hold. And when that happens, the inevitable question will be: what's in it for me?
To survive in this increasingly competitive environment, companies will need to provide a clear answer. It won’t be enough to simply ask for data; they’ll have to offer something of real value. This is where product and UX teams face their biggest challenge: creating tangible benefits, something that makes consumers think, "it’s worth sharing." The challenge will no longer be just attracting consent but keeping it.
If you know anyone who would like to receive this e-mail or who is fascinated by the possibilities of financial innovation, I’d really appreciate you forwarding this email their way!
Until the next!
Walter Pereira
Disclaimer: The opinions expressed here are solely the responsibility of the author, Walter Pereira, and do not necessarily reflect the views of the sponsors, partners, or clients of W Fintechs.
https://www.statista.com/statistics/1185888/worldwide-global-datasphere-unique-replicated-data/
https://thebusinessdive.com/ai-productivity-statistics#top-ai-productivity-statistics-in-2024
https://bi-survey.com/decision-making-no-information
https://bi-survey.com/decision-making-no-information
https://www.pwc.com.br/pt/consultoria-negocios/assets/bench_financas_baixa.pdf
https://www.cio.com/article/220347/ai-unleashes-the-power-of-unstructured-data.html
https://www.statista.com/statistics/1132224/worldwide-daas-market/
https://www.statista.com/statistics/1234242/analytics-as-a-service-global-market-size/